Twitterから2億人超の情報が流出。その調査メモ。
最終更新 2023/03/04 20:13
2021年に2億人超のアカウント情報がTwitterから流失したとみられている。
流出が発覚した直後、私は独自に流失データの分析を行っていた。その分析手法や結果について、中学校卒業まじかで幾分か時間のある今のうちに、記録資料としてブログ記事の形で残しておこうと思う。
私の活動はリスクの高いグレーハット的なものであり、きっと万人には受け入れられないだろうから、この記事の公開はおそらく数年後以降になるだろうと考えている。
第一章 - データの入手
2023年1月6日、私に一つの連絡が飛び込んできた - 「ツイッターのリークデータの件について、調べて頂けないでしょうか」。
当時仲の良かった共同通信社の記者からだった。私は定期テスト前であるにも関わらず、突然舞い込んできた依頼を快く承った。
流出したデータが、Ryushiと名乗るユーザーによって「BreachForums」と呼ばれる海外のサイトにアップロードされているという情報を得て、私は早速TorブラウザからBreachForumsのOnionミラーへアクセスした。
BreachForumsは会員制のサービスで、誰でも無料で登録できる。 私は既にアカウントを所有していたが、いずれインフラが現地警察に押収されたとき司法に追跡されるリスクを考えて、新しいアカウントを匿名で作成した。 登録に使用したメールアドレスは、セキュリティやプライバシー重視で有名なProtonMailのものだ。
Protonは以前当局にメタデータを提供したとの噂を聞いていたため、ProtonMailアカウントの作成もTor経由で行い、その認証メールにはmail-testerと呼ばれる「メールの信用性をテストできるサービス」を登録した。 mail-testerの本来の目的とは異なり、悪用したと言われても仕方のないことであるが、私はこれにより極めて匿名性の高いBreachForumsのアカウントを作成することができた。
アカウントの作成に成功し、ダウンロードを行おうとしたが、ダウンロードには「クレジット」と呼ばれる手数料の支払いが必要だった。 もちろん、クレジットカードなどのKYCを行っている方法で決済を行っては、匿名でアカウントを作成した意味がなくなってしまう。
私は、匿名性を保持したまま決済するため、仮想通貨「Monero」で支払いを行った。 Moneroは秘匿性の高い仮想通貨であり、ステルスアドレスやリング署名と呼ばれる技術により安全かつ匿名に取引ができるという特徴を持つ。
私はMoneroで30クレジット(0.0550 XMR ~ 1400円; この記事が読まれている頃にはもう少しインフレしているかもしれない)を購入し、その内の8クレジットを使ってデータのダウンロード権限を入手した。 そこには二つのファイルがあり、一度は自宅のPCにデータを落とそうとしたが、一つ目のファイルのサイズが大きく(圧縮された状態で約13.4GB)、ダウンロードに大変時間がかかることから、スウェーデンに契約している防弾VPSへcurlで落とした。
nohup torsocks curl -vv {redacted}.onion/share/twitter/twitter.rar -o twitter.rar &
< HTTP/1.1 200 OK
< Server: nginx/1.18.0
< Date: Fri, 06 Jan 2023 15:48:48 GMT
< Content-Type: application/x-rar-compressed
< Content-Length: 14410334383
< Last-Modified: Wed, 04 Jan 2023 03:57:48 GMT
< Connection: keep-alive
< ETag: "63b4f93c-35aec40af"
< Accept-Ranges: bytes
<
{ [2537 bytes data]
100 13.4G 100 13.4G 0 0 4946k 0 0:47:25 0:47:25 --:--:-- 1664kそこからVPN経由で自分のPCへデータを移動し、更に自己暗号化機能を持つUSBへデータを移動した。 そのUSBとは、KingstonのDataTraveler Locker+ G3 DTLPG3である。 自己暗号化やキルスイッチ(自己初期化)、パスワード保護機能を持つ - 警察に押収された際に、データを見られないためである。 また、私は偽のパスワードを入力すると一見パスワードが合っているかように振る舞い、内部データを上書き削除する仕様も独自に実装した。
私は、個人情報を悪用するためにリークデータを入手したのではない。 これを分析して、その統計データを提供したり、特定のアカウントが流出しているか簡単に調べられるツールを開発するためである。 だが、このリークデータを入手すること自体が犯罪若しくはその幇助に当たる可能性があり、ゆえに善良な研究者を名乗ることはできなかった。 すなわち、正義のハッカーというきれいごとでは済まないのだ。 悪のクラッカーとして警察に追跡される可能性も十分にあった。
第二章 - 分析
入手したRARの圧縮ファイルを展開すると、合計59GBの6つのテキストファイルが出てきた。 そのファイル名は、「Hits (3).txt」「Hits (4).txt」「Hits (6).txt」「Hits (7).txt」「Hits (8).txt」「Hits (9).txt」である。 そこで、私はテキストファイルをC#で分析することにした。
C#で分析すると言っても、一行ずつ読み込む以外に方法がなかった。wcコマンドで行数をカウントすると、なんと約4億6096万行となった。 一部のメディアは約2億2160万行と報じていたが、この情報は「重複を削除した上での行数」であるか、又は改行コードのカウント方法に差異があるのではないかと推測する。 どちらにせよ、これほどの行数のテキストファイルを現実的な時間で分析するには、効率的なアルゴリズムが必要だった。 私は、ファイルのI/Oを非同期で実装し、複数スレッドで行を読み取ることにより毎秒500万行を処理できるようにした(CPUはIntel i9 12900K、メモリーは96GB)。
まず初めに、リークデータをSQLのデータベースに変換することを試みた。 というのも、SQLのデータベースであれば容易に重複しているアカウントを摘出したり、データの検索や件数の取得が行えるからだ。 しかし、メモリー不足に陥った上に、分析の速度的に不可能だった。 正規表現でデータを整理するだけならば毎秒500万行だった処理速度は、そのデータをSQLにinsertする処理を実装すると、毎秒2万行にまで低迷したのだ。 この速度では話にならないほどの時間がかかるため、データベース化は諦めた。
そこで、C#のプログラム側で統計を取り、その結果を変数に記録することにした。 その統計項目は、「読み取った行数」「正規表現に一致するデータ数」「正規表現に一致しないデータ数」「データの合計サイズ」「メールアドレスのドメイン」「アカウントを作成した年」である。 この統計の結果を以下に示す。
File.ReadLines()により読み取った行数: 454632727
正規表現に一致するデータ数 : 451391683
正規表現に一致しないデータ数 : 3241044
データの合計サイズ : 63521845998
メールアドレスのドメイン(トップ20) :
[gmail.com] => 155342202 (34%)
[yahoo.com] => 87726760 (19%)
[hotmail.com] => 77412135 (17%)
[aol.com] => 11515402 (2%)
[hotmail.co.uk] => 9167180 (2%)
[hotmail.fr] => 8615431 (1%)
[mail.ru] => 6045928 (1%)
[live.com] => 4563019 (1%)
[yahoo.co.uk] => 3623180 (0%)
[msn.com] => 3492369 (0%)
[yahoo.fr] => 3297881 (0%)
[comcast.net] => 2870054 (0%)
[ymail.com] => 2455703 (0%)
[icloud.com] => 2410264 (0%)
[live.fr] => 2125404 (0%)
[yandex.ru] => 1977872 (0%)
[live.co.uk] => 1700912 (0%)
[web.de] => 1681969 (0%)
[yahoo.co.jp] => 1642258 (0%)
[sbcglobal.net] => 1536785 (0%)
アカウントを作成した年 :
[2011] => 85228865 (18%)
[2012] => 78036813 (17%)
[2013] => 55583149 (12%)
[2009] => 43862233 (9%)
[2010] => 43171413 (9%)
[2014] => 42159404 (9%)
[2015] => 31456833 (6%)
[2016] => 24382270 (5%)
[2017] => 20378570 (4%)
[2018] => 10100653 (2%)
[2020] => 7269022 (1%)
[2019] => 6778564 (1%)
[2021] => 5933445 (1%)
[2008] => 4885392 (1%)
[2007] => 1133614 (0%)
[2006] => 40922 (0%)
[1970] => 96 (0%) ← Unix時間の0であり、該当アカウントは全て凍結されていた。
[2000] => 1 (0%) ← バグと推測される。本当は重複アカウント数の統計も取りたかったが、C#の配列の最大長(=INT_MAX)を超えるため、途中でプログラムが強制終了してしまった。

また、流出したアカウントに日本人のアカウントがどれだけ含まれているのかを調べるため、ユーザー名に漢字や平仮名、カタカナが含まれているアカウントだけを抽出した。 その結果、リークデータの内「ユーザー名にひらがな若しくはカタカナを含むアカウント」は5,179,159アカウント存在しており、「ユーザー名に漢字を含むアカウント」は2,495,805アカウント存在していた。
これは一件多いようにも見えるが、全体の1%未満である。 「ユーザー名にひらがな若しくはカタカナを含むアカウント」はほぼ確実に日本人であると推測されるが、「ユーザー名に漢字を含むアカウント」は中国人などである可能性もあるため、どこまでが日本人なのかは不明だった。 また「ユーザー名にひらがな、カタカナ、漢字のいずれかを含むアカウント」だけを抽出して、別ファイルに書き込んだが、そのファイルサイズは約100MBだった。 これについては、Cheena氏も「結構偏りあると思う、メアドのソースも別サイトのデータからじゃないかな」と述べている(Twitter)。
第三章 - 有名人のデータ
流出したアカウントの件数は億単位であり、その中には当然一定の知名度を持つ有名人のデータも含まれている。 有名人のアカウントに個人のメールアドレスが登録されていれば、OSINTにより本名を特定できる事があった。 例えば、Ghuntを使えばGmailアドレスからGoogleアカウントの名前を特定できる。
また、メディアは、PV数を増やすために有名人や政治家の具体的な名前を載せたがった。 その候補には何人か挙げられたが、最終的には「日本国の政府関係アカウントであり、かつメールアドレスに衆院事務局から割り当てられたアドレスを登録していたことが問題」として加藤勝信厚生労働相などが大々的に取り上げられた。
情報提供先の共同通信社は「厚労相のメアド、闇サイトに流出 ツイッターで使用、複数省庁も」というタイトルの記事を執筆し、記事はTwitterで万バズ・Yahooニュースのトップに表示されるほどの勢いで「炎上」を起こした。 狙い通りだ。
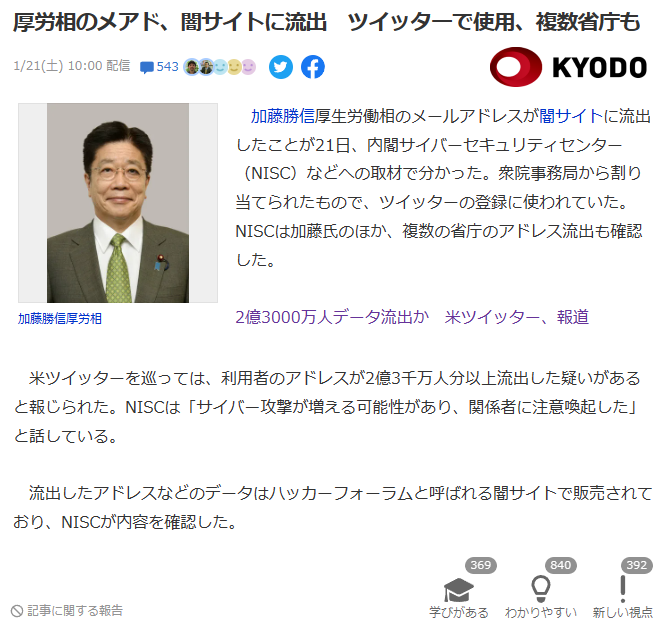
厚労相のメアド、闇サイトに流出 ツイッターで使用、複数省庁もから引用
私は、改めてメディアの影響力の強さを実感した。 Twitterを触っていてもこの記事ばかりがタイムラインに流れてきて、一種の恐怖すら感じるほどだった。 ふとした中学生の調査が世論を大きく動かしたり、人の印象を操作できる - 年齢に関係なく社会的影響力を持てるのは、インターネット時代に特有の性質とも言えるだろう。
第四章 - 漏洩確認ツールの開発
データの分析を終えた私は、誰でも手軽にアカウントが漏洩しているか確認できるツール「Twitter Leaked Checker」の開発に取り掛かった。 リストに特定のスクリーンネームを持つアカウントが含まれているのかを確認できればいいため、メールアドレスなどの情報は不要である。 そこで、まずリークデータの中からスクリーンネームだけを抽出して、リーク一覧ファイルとして保存した。
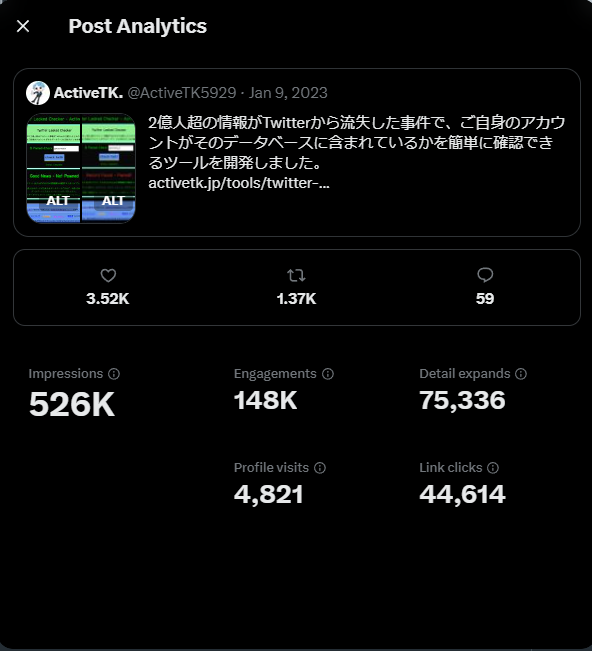
クライアントサイドのHTMLとJavaScript、CSSを数分で実装し、サーバー側にはPHPでスクリーンネームがリーク一覧ファイルに含まれているかを判定する処理を実装した。 しかし、リーク一覧ファイルだけでも数GBあったため、当初のアルゴリズムでは確認を行うのに数十秒~数分かかった。 初期はそれで十分だったが、Twitterで当該ツールを宣伝したところ、一瞬の内に拡散され、50万インプレッション・4万リンククリックとなった。 私の契約しているスターサーバーはこの急激なアクセス増加に耐え切れず、一度落ちかけてしまった。
同じサーバーを契約していた人に申し訳ないと思い、アルゴリズムの改善を行った。 具体的には、スクリーンネームの先頭4文字を使ってファイル分けをすることにしたのだ。 一つの巨大なファイルに含まれているか判定しているからリソースを多く消費するのであって、分割されたファイルが小さければ短時間と少ないリソースで検索できる。 このアルゴリズムの改善によって、最終的にほぼ全てのリクエストに1秒以内で応答することができた。
また、サーバー負荷軽減のため、結果をCDNのCloudFlareにキャッシュさせた。 これにより、スターサーバーは通常通りの状態に復旧した。
Twitter Leaked Checker - ActiveTK.jp
なお、簡易的な標本調査・フェルミ推定にすぎないが、Twitterにおけるn=1,833のアンケート調査により日本のアクティブユーザーの流失率は15%程度だと判明した。 日本のTwitterユーザー数を6000万人と仮定すると、流出したデータには約900万人の日本人が含まれていると推測される。人口比から考えると、14人に1人が被害者ということになる。
大規模なサービスでインシデントが発生すると容易に数百万人のオーダーの被害者が発生することから、莫大なユーザー数を抱える事業者にはセキュリティに関して相当気を付けてもらいたいところだ。