【悪質】archive.todayのアーカイブ作成を拒否する方法
最終更新 2023/09/29 20:55
archive.todayは、Webアーカイブを簡単に誰でも作成できるサービスです。
Webサイトの過去の状態を記録しておきたい場合や、消えてしまったサイトを閲覧したい場合などに活用できます。
しかし、このサービスはweb.archive.orgなどの他のWebアーカイバーとは異なり、以下のような特徴があります。
・ほぼ100%、アーカイブ削除の申請を受け付けない。
・robots.txtやrobotsタグの設定を無視してアーカイブを作成する。
・生成されたアーカイブページは、検索エンジンにインデックスされる。
1つ目と2つ目の特徴は「情報の保存」という観点から保護されるべきと考えることができるものの、3つ目の特徴はサイト運営者からすると迷惑な話です。アクセス数を奪われますし、勝手にテキストが使われた挙句に広告で画面が埋められます。
そこで、本記事ではarchive.todayによるアーカイブ作成を拒否する方法をご紹介させて頂きます。
アーカイブ作成を拒否する方法
archive.todayは、しばしばサーバーのIPアドレスを変更したりドメインを移動したりするため、クローラーのIPアドレスをリスト化して拒否することは困難です。
そこで、ユーザー端末を言語設定やディスプレイ情報、WebRTCなどに基づいてスコア化し、archive.todayのクローラーを判別するスクリプト「archive-today.blocker.js」を開発してみました。
こちらのスクリプトをサイトに導入することにより、archive.todayのクローラーを自動で弾くことができます。
利用方法は簡単で、サイトのHTMLソースコードに以下の行を追加して下さい。head内がオススメです。
<script src="https://code.activetk.jp/archive-today.blocker.js" defer></script>結果
上記のスクリプトを導入したサイトをアーカイブしようとすると、以下のような画面となります。
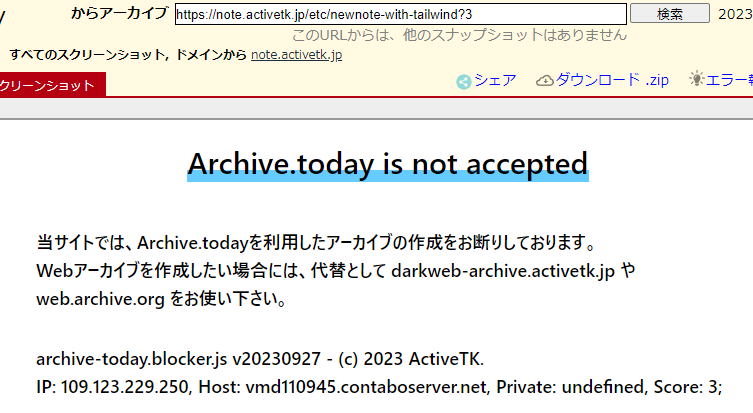
このように、サイトが表示される代わりにメッセージが表示されるようになります。
代替のアーカイブサービス
私は、この前(といっても中3のとき)にarchive.phの代替となる魚拓サービス「DarkWeb Archive」を開発しました。
こちらのアーカイバーでは、HTMLデータのみならずHTTPヘッダーやデータのハッシュなどが保存されるのが特徴で、「後から振り返るため」よりも「存在していた証拠として」の利用を想定しています。
また、通常のクリアネット上のサイトのみならず、onionドメインのサイトも保存できるのも特徴です。ぜひお試しください!